REPAIR: Robust Editing via Progressive Adaptive Intervention and Reintegration
Introducing REPAIR, the framework that lets your LLM evolve.
Dr. Sarah Kim
CTO & Co-Founder
Beyond Static AI: Introducing REPAIR, the Framework That Lets Your LLM Evolve
Large Language Models (LLMs) are transforming our digital world with their impressive capabilities. But they have an inherent flaw: their knowledge is frozen in time. Correcting an error or teaching them new information requires costly retraining, a process fraught with the risk of "catastrophic forgetting" and unintended side effects.
In a world that constantly changes, an AI that can't learn and adapt is a depreciating asset. What if we could perform surgical updates to a model's knowledge with a precisely, safely, and low cost way without disrupting its existing abilities?
Now, we can. We are thrilled to introduce REPAIR, a revolutionary framework from ContiAl Research designed for the lifelong editing of LLMs.
What is REPAIR?
REPAIR, which stands for Robust Editing via Progressive Adaptive Intervention and Reintegration, is a novel lifelong editing framework. Its purpose is to make model updates precise and affordable while carefully preserving non-target knowledge. Think of it as an intelligent "immune system" for your LLM, one that can integrate new knowledge and heal errors without causing systemic issues.
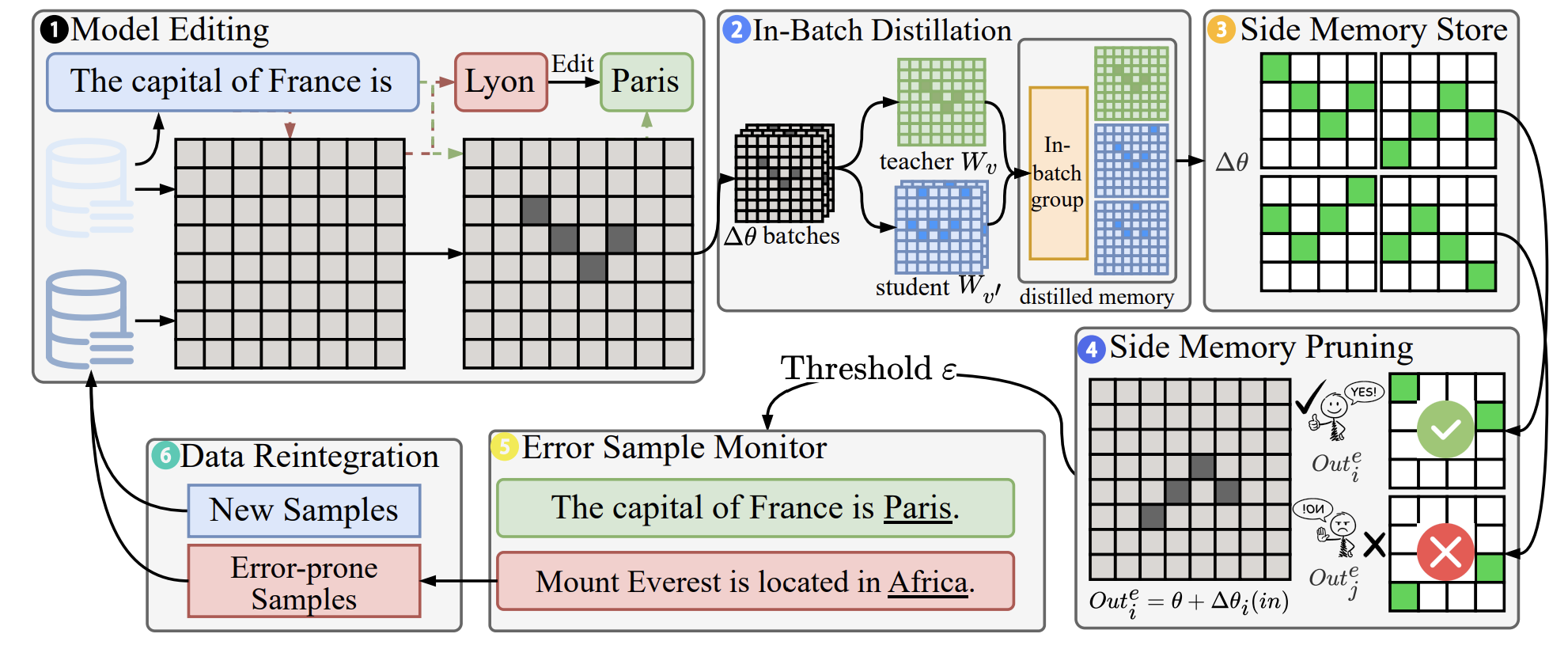
The Three Pillars of REPAIR's Innovation
REPAIR's remarkable effectiveness stems from its unique, integrated design built on three core strategies:
- Closed-Loop Feedback with Dynamic Memory Management: Unlike "fire-and-forget" editing methods, REPAIR employs a closed-loop feedback mechanism that acts as an "Error Monitor". It constantly assesses the performance of each edit. If a knowledge update leads to instability or conflicts, the system can selectively prune or re-initialize the underperforming components, ensuring the model's long-term health during large-scale sequential edits.
- Distribution-Aware Optimization: To ensure edits are robust and generalizable, REPAIR goes beyond simple prompt-matching. It intelligently groups similar samples and uses "in-batch knowledge distillation" to foster consistency. This encourages the model to learn the underlying concept, not just memorize a specific phrase, allowing the new knowledge to apply across various paraphrases and related contexts.
- Frequent Knowledge Fusion with Locality Guardrails: To prevent information loss, REPAIR increases the frequency of merging new knowledge with the model's existing parameter base. Critically, before any integration, it validates the update with "locality guards" to prevent unintended ripple effects on unrelated knowledge. This ensures that fixing one problem doesn't accidentally create another.
The Results Speak for Themselves

REPAIR was rigorously tested on a diverse range of models, including LLaMA-3, Qwen-2.5, and GPT-2-XL, with outstanding results:
- Accuracy Boost: Across multiple model families, REPAIR boosts editing accuracy by an impressive 10%-30%.
- Forgetting is Minimized: The framework significantly reduces the problem of knowledge forgetting that plagues other methods.
- Superior Scalability: In large-scale sequential editing scenarios (e.g., 1000 edits), where other methods degrade sharply, REPAIR's dynamic adjustment mechanism preserves robustness and achieves the best overall performance.
- Effective Hallucination Mitigation: REPAIR is highly effective at reducing model hallucinations while preserving its performance on unrelated queries, striking a crucial balance between correction and stability.
N = 1
| Method | Model | Rel. | Gen. | Loc. | OP. |
|---|---|---|---|---|---|
| FT-L | LLaMA-3-8B (ZsRE) | 0.57 | 0.52 | 0.96 | 0.66 |
| FT-EWC | LLaMA-3-8B (ZsRE) | 0.96 | 0.93 | 0.02 | 0.26 |
| MEND | LLaMA-3-8B (ZsRE) | 0.95 | 0.93 | 0.96 | 0.95 |
| ROME | LLaMA-3-8B (ZsRE) | 0.85 | 0.80 | 0.99 | 0.88 |
| MEMIT-M | LLaMA-3-8B (ZsRE) | 0.84 | 0.81 | 0.99 | 0.88 |
| DEFER | LLaMA-3-8B (ZsRE) | 0.68 | 0.58 | 0.56 | 0.61 |
| GRACE | LLaMA-3-8B (ZsRE) | 0.97 | 0.36 | 1.00 | 0.71 |
| WISE | LLaMA-3-8B (ZsRE) | 0.94 | 0.92 | 1.00 | 0.95 |
| REPAIR | LLaMA-3-8B (ZsRE) | 0.94 | 0.92 | 1.00 | 0.95 |
| --- | --- | --- | --- | --- | --- |
| FT-L | Qwen2.5-7B (ZsRE) | 0.68 | 0.63 | 0.93 | 0.74 |
| FT-EWC | Qwen2.5-7B (ZsRE) | 0.97 | 0.92 | 0.05 | 0.35 |
| MEND | Qwen2.5-7B (ZsRE) | 0.96 | 0.95 | 0.96 | 0.96 |
| ROME | Qwen2.5-7B (ZsRE) | 0.90 | 0.89 | 0.99 | 0.93 |
| MEMIT-M | Qwen2.5-7B (ZsRE) | 0.84 | 0.81 | 0.99 | 0.88 |
| DEFER | Qwen2.5-7B (ZsRE) | 0.74 | 0.67 | 0.88 | 0.76 |
| GRACE | Qwen2.5-7B (ZsRE) | 0.97 | 0.41 | 0.98 | 0.73 |
| WISE | Qwen2.5-7B (ZsRE) | 0.97 | 0.95 | 0.98 | 0.97 |
| REPAIR | Qwen2.5-7B (ZsRE) | 0.98 | 0.95 | 1.00 | 0.98 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.71 | 0.68 | 0.93 | 0.77 |
| FT-EWC | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.93 | 0.91 | 0.33 | 0.65 |
| MEND | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.91 | 0.87 | 0.95 | 0.91 |
| ROME | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.86 | 0.83 | 0.97 | 0.88 |
| MEMIT-M | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.86 | 0.87 | 0.97 | 0.90 |
| DEFER | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.68 | 0.58 | 0.47 | 0.35 |
| GRACE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.96 | 0.47 | 0.99 | 0.76 |
| WISE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.89 | 0.91 | 0.98 | 0.93 |
| REPAIR | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.98 | 0.93 | 0.98 | 0.96 ↑ |
N = 30
| Method | Model | Rel. | Gen. | Loc. | OP. |
|---|---|---|---|---|---|
| FT-L | LLaMA-3-8B (ZsRE) | 0.35 | 0.35 | 0.52 | 0.39 |
| FT-EWC | LLaMA-3-8B (ZsRE) | 0.78 | 0.76 | 0.02 | 0.23 |
| MEND | LLaMA-3-8B (ZsRE) | 0.24 | 0.25 | 0.18 | 0.22 |
| ROME | LLaMA-3-8B (ZsRE) | 0.61 | 0.60 | 0.68 | 0.63 |
| MEMIT-M | LLaMA-3-8B (ZsRE) | 0.73 | 0.72 | 0.95 | 0.79 |
| DEFER | LLaMA-3-8B (ZsRE) | 0.65 | 0.47 | 0.36 | 0.49 |
| GRACE | LLaMA-3-8B (ZsRE) | 0.96 | 0.17 | 1.00 | 0.55 |
| WISE | LLaMA-3-8B (ZsRE) | 0.62 | 0.60 | 0.86 | 0.68 |
| REPAIR | LLaMA-3-8B (ZsRE) | 0.93 | 0.90 | 0.87 | 0.89 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | Qwen2.5-7B (ZsRE) | 0.28 | 0.23 | 0.44 | 0.30 |
| FT-EWC | Qwen2.5-7B (ZsRE) | 0.82 | 0.80 | 0.02 | 0.24 |
| MEND | Qwen2.5-7B (ZsRE) | 0.31 | 0.31 | 0.27 | 0.29 |
| ROME | Qwen2.5-7B (ZsRE) | 0.77 | 0.73 | 0.52 | 0.66 |
| MEMIT-M | Qwen2.5-7B (ZsRE) | 0.73 | 0.72 | 0.95 | 0.79 |
| DEFER | Qwen2.5-7B (ZsRE) | 0.58 | 0.51 | 0.44 | 0.51 |
| GRACE | Qwen2.5-7B (ZsRE) | 0.97 | 0.2 | 1.00 | 0.58 |
| WISE | Qwen2.5-7B (ZsRE) | 0.79 | 0.73 | 0.91 | 0.80 |
| REPAIR | Qwen2.5-7B (ZsRE) | 0.93 | 0.90 | 0.93 | 0.92 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.26 | 0.20 | 0.76 | 0.34 |
| FT-EWC | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.70 | 0.70 | 0.18 | 0.45 |
| MEND | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.43 | 0.38 | 0.10 | 0.25 |
| ROME | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.72 | 0.71 | 0.67 | 0.70 |
| MEMIT-M | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.78 | 0.77 | 0.82 | 0.79 |
| DEFER | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.63 | 0.61 | 0.51 | 0.58 |
| GRACE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.93 | 0.24 | 0.91 | 0.59 |
| WISE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.76 | 0.74 | 0.89 | 0.79 |
| REPAIR | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.84 | 0.83 | 0.91 | 0.86 ↑ |
N = 120
| Method | Model | Rel. | Gen. | Loc. | OP. |
|---|---|---|---|---|---|
| FT-L | LLaMA-3-8B (ZsRE) | 0.29 | 0.26 | 0.21 | 0.25 |
| FT-EWC | LLaMA-3-8B (ZsRE) | 0.76 | 0.76 | 0.08 | 0.36 |
| MEND | LLaMA-3-8B (ZsRE) | 0.08 | 0.07 | 0.00 | 0.00 |
| ROME | LLaMA-3-8B (ZsRE) | 0.22 | 0.22 | 0.04 | 0.12 |
| MEMIT-M | LLaMA-3-8B (ZsRE) | 0.70 | 0.65 | 0.82 | 0.72 |
| DEFER | LLaMA-3-8B (ZsRE) | 0.20 | 0.12 | 0.27 | 0.20 |
| GRACE | LLaMA-3-8B (ZsRE) | 0.94 | 0.14 | 1.00 | 0.51 |
| WISE | LLaMA-3-8B (ZsRE) | 0.57 | 0.58 | 0.87 | 0.66 |
| REPAIR | LLaMA-3-8B (ZsRE) | 0.76 | 0.74 | 1.00 | 0.83 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | Qwen2.5-7B (ZsRE) | 0.13 | 0.11 | 0.10 | 0.11 |
| FT-EWC | Qwen2.5-7B (ZsRE) | 0.71 | 0.69 | 0.05 | 0.29 |
| MEND | Qwen2.5-7B (ZsRE) | 0.15 | 0.14 | 0.03 | 0.09 |
| ROME | Qwen2.5-7B (ZsRE) | 0.31 | 0.28 | 0.03 | 0.14 |
| MEMIT-M | Qwen2.5-7B (ZsRE) | 0.70 | 0.65 | 0.82 | 0.72 |
| DEFER | Qwen2.5-7B (ZsRE) | 0.22 | 0.21 | 0.43 | 0.27 |
| GRACE | Qwen2.5-7B (ZsRE) | 0.95 | 0.08 | 0.98 | 0.42 |
| WISE | Qwen2.5-7B (ZsRE) | 0.59 | 0.57 | 0.92 | 0.68 |
| REPAIR | Qwen2.5-7B (ZsRE) | 0.81 | 0.80 | 0.92 | 0.84 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.13 | 0.11 | 0.37 | 0.17 |
| FT-EWC | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.42 | 0.41 | 0.07 | 0.23 |
| MEND | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.24 | 0.23 | 0.08 | 0.16 |
| ROME | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.18 | 0.18 | 0.02 | 0.09 |
| MEMIT-M | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.54 | 0.51 | 0.77 | 0.60 |
| DEFER | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.17 | 0.15 | 0.33 | 0.20 |
| GRACE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.76 | 0.13 | 0.89 | 0.44 |
| WISE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.64 | 0.65 | 0.83 | 0.70 |
| REPAIR | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.71 | 0.69 | 0.90 | 0.76 ↑ |
N = 1000
| Method | Model | Rel. | Gen. | Loc. | OP. |
|---|---|---|---|---|---|
| FT-L | LLaMA-3-8B (ZsRE) | 0.19 | 0.15 | 0.02 | 0.08 |
| FT-EWC | LLaMA-3-8B (ZsRE) | 0.69 | 0.67 | 0.08 | 0.33 |
| MEND | LLaMA-3-8B (ZsRE) | 0.00 | 0.00 | 0.00 | 0.00 |
| ROME | LLaMA-3-8B (ZsRE) | 0.01 | 0.01 | 0.01 | 0.01 |
| MEMIT-M | LLaMA-3-8B (ZsRE) | 0.63 | 0.63 | 0.62 | 0.63 |
| DEFER | LLaMA-3-8B (ZsRE) | 0.03 | 0.03 | 0.74 | 0.27 |
| GRACE | LLaMA-3-8B (ZsRE) | 0.93 | 0.08 | 1.00 | 0.42 |
| WISE | LLaMA-3-8B (ZsRE) | 0.45 | 0.44 | 0.51 | 0.47 |
| REPAIR | LLaMA-3-8B (ZsRE) | 0.68 | 0.65 | 0.89 | 0.73 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | Qwen2.5-7B (ZsRE) | 0.08 | 0.06 | 0.02 | 0.05 |
| FT-EWC | Qwen2.5-7B (ZsRE) | 0.58 | 0.56 | 0.03 | 0.21 |
| MEND | Qwen2.5-7B (ZsRE) | 0.02 | 0.02 | 0.00 | 0.00 |
| ROME | Qwen2.5-7B (ZsRE) | 0.01 | 0.02 | 0.00 | 0.00 |
| MEMIT-M | Qwen2.5-7B (ZsRE) | 0.52 | 0.51 | 0.57 | 0.53 |
| DEFER | Qwen2.5-7B (ZsRE) | 0.14 | 0.08 | 0.25 | 0.14 |
| GRACE | Qwen2.5-7B (ZsRE) | 0.94 | 0.02 | 1.00 | 0.27 |
| WISE | Qwen2.5-7B (ZsRE) | 0.44 | 0.41 | 0.72 | 0.51 |
| REPAIR | Qwen2.5-7B (ZsRE) | 0.72 | 0.70 | 0.67 | 0.69 ↑ |
| --- | --- | --- | --- | --- | --- |
| FT-L | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.02 | 0.02 | 0.08 | 0.03 |
| FT-EWC | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.18 | 0.15 | 0.02 | 0.08 |
| MEND | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.03 | 0.03 | 0.02 | 0.05 |
| ROME | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.01 | 0.0 | 0.01 | 0.00 |
| MEMIT-M | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.38 | 0.38 | 0.62 | 0.45 |
| DEFER | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.07 | 0.07 | 0.12 | 0.08 |
| GRACE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.63 | 0.07 | 0.81 | 0.33 |
| WISE | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.47 | 0.38 | 0.61 | 0.48 |
| REPAIR | DeepSeek‑R1‑1.5B (WikiBigEdit) | 0.58 | 0.54 | 0.81 | 0.63 ↑ |
Comparative results show REPAIR consistently achieving a higher Overall Performance (OP) across different models and edit scales, demonstrating its superior balance of Reliability, Generalization, and Locality.
The Path Forward
REPAIR introduces a robust and scalable framework for developing the next generation of reliable and continually evolving LLMs. It is a critical step towards creating truly dynamic AI systems that can learn, adapt, and stay relevant over time. This work opens up new possibilities for anyone looking to maintain and enhance the capabilities of large-scale models in a safe and efficient manner.
Ready to dive deeper into the technical details? Read the full paper on arXiv: arXiv:2510.01879v1.